Zhengbo Zhang, Zhigang Tu*, Junsong Yuan, De Wen Soh, Bo Du.
Leveraging Text-to-Image Diffusion Models for Unsupervised Visual Object Tracking.
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026.
(通信作者, IF=20.4, CCF A类期刊)
Yuanjun Tan, Aoran Xiao, Liqian Deng, Zhigang Tu*.
DarkAct: A RGB-Thermal Dataset and Fusion Framework for Multimodal Low-Light Action Recognition.
CVPR, 2026.
(通讯作者, CCF-A类会议,人工智能&计算机视觉三大顶会之一)
Zhengbo Zhang, Mark He Huang, Zhigang Tu*, Ming-Hsuan Yang.
DART: Difficulty-Adaptive Routing for Zero-Shot Video Temporal Grounding.
ECCV, 2026.
(通信作者, CAAI A类会议)
Shihao Cheng, J. Zhang, Q. Song, S. Liu, G. Zhi, X. Zhang, C. Zhang, Xuelong Li, Zhigang Tu*.
Unison: Harmonizing Motion, Speech, and Sound for Human-Centric Audio-Video Generation.
ECCV, 2026.
(通信作者, CAAI A类会议)
Mengfei Zhang, Jinlu Zhang, Zhigang Tu*.
Uni-HOI: A Unified framework for Learning the Joint distribution of Text and Human-Object Interaction .
ACM MM, 2026.
(通讯作者, CCF-A类会议,多媒体领域顶会)
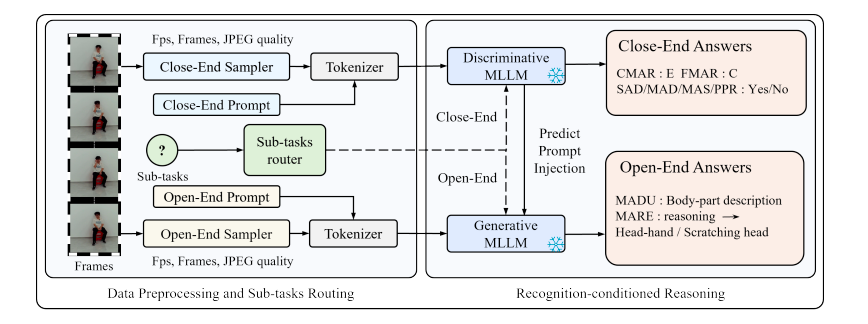
Fengshun Wang, Jin'ang Han, Zhigang Tu*.
Recognition-Conditioned Reasoning: A Training-Free Multimodal-LLM Pipeline for Fine-Grained Micro-Action Understanding .
ACM MM, 2026.
(通讯作者, CCF-A类会议,多媒体领域顶会)
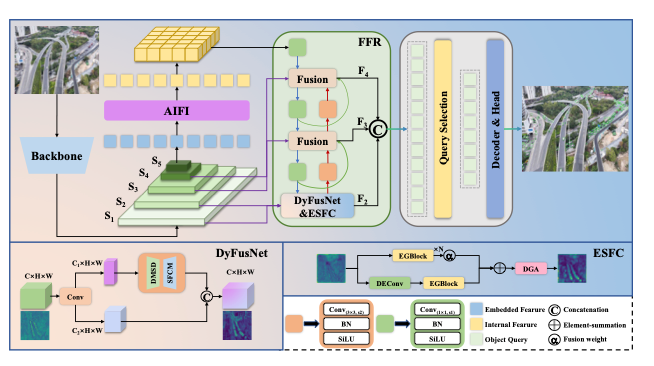
Yu Xia, Chang Liu, Tianqi Xiang, Yang Cong, Zhigang Tu*.
EFSI-DETR: Efficient Frequency-Semantic Integration for Real-Time Small Object Detection in UAV Imagery.
IEEE Transactions on Multimedia, 2026.
(通讯作者, IF=9.9, 中科院1区Top)
2025
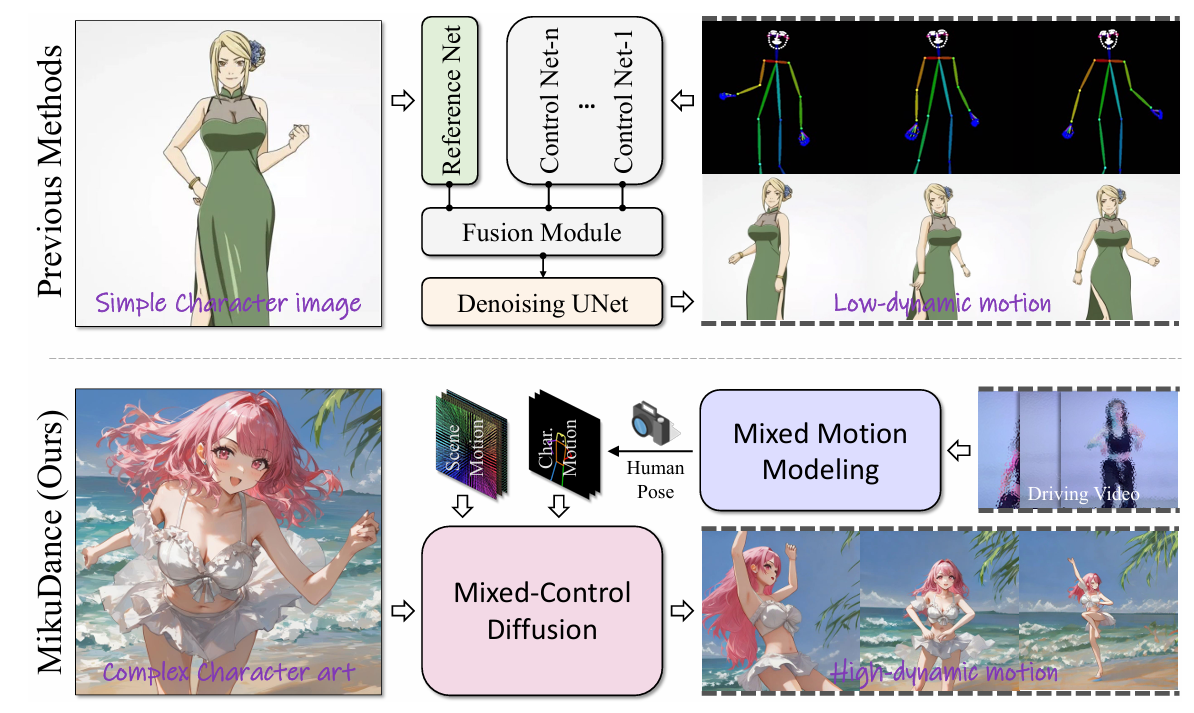
Jiaxu Zhang, Xianfang Zeng, Xin Chen, Wei Zuo, Gang Yu, Zhigang Tu*.
MikuDance: Animating Character Art with Mixed Motion Dynamics.
ICCV Oral Presentation, 2025.
(通讯作者, CCF-A类会议,人工智能&计算机视觉三大顶会之一,录用率<2%)
PDF
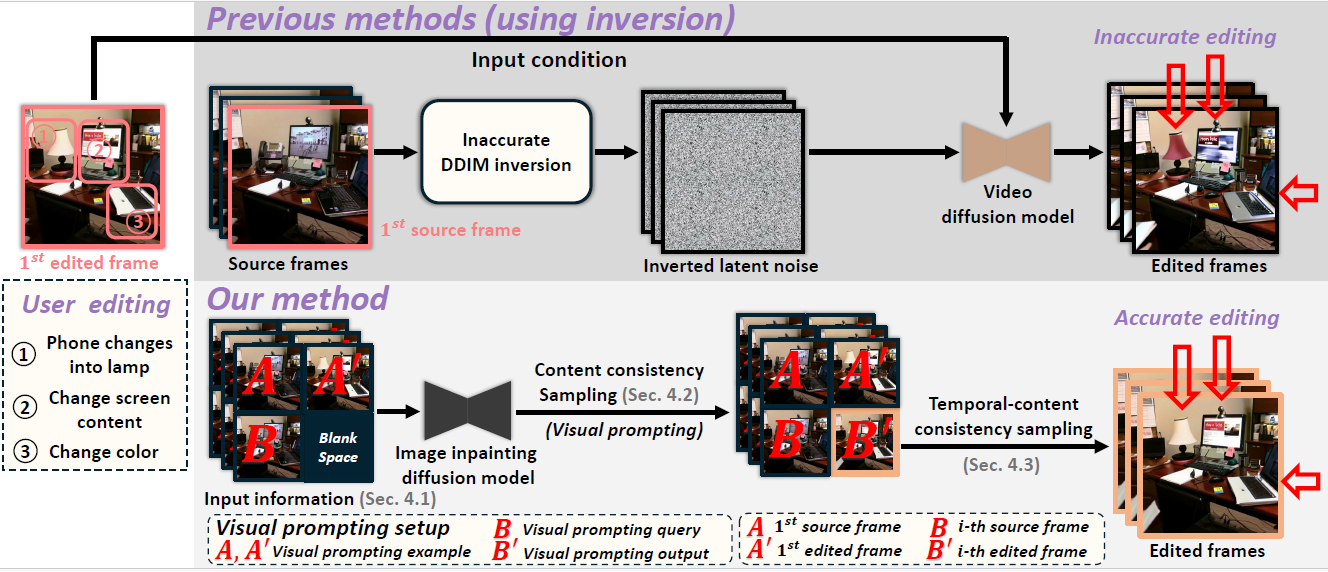
Zhengbo Zhang#, Yuxi Zhou#, Duo Peng, Joo Hwee Lim, Zhigang Tu*, De Wen Soh, Lin Geng Foo.
Visual Prompting for One-shot Controllable Video Editing without Inversion.
CVPR, 2025. (通讯作者, CCF-A类会议, 人工智能&计算机视觉三大顶会之一)
PDF
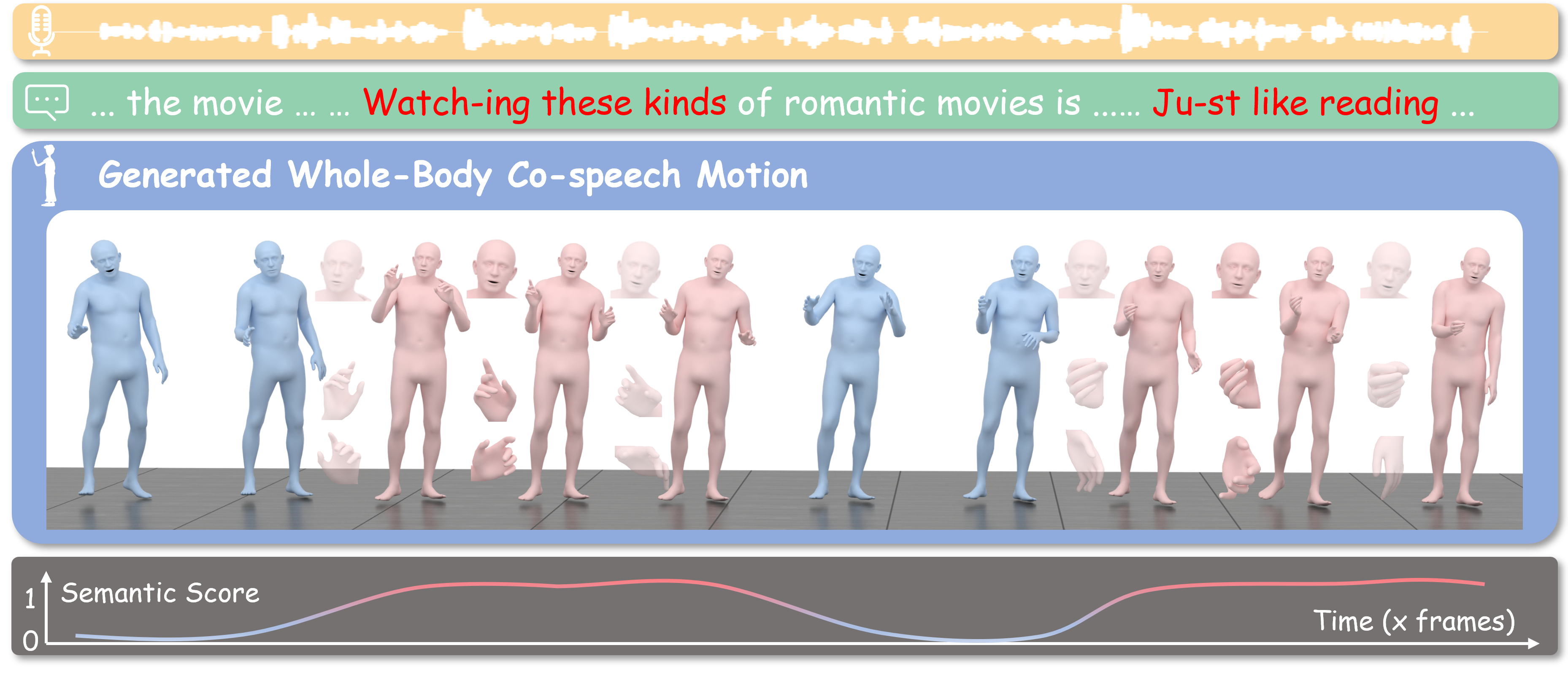
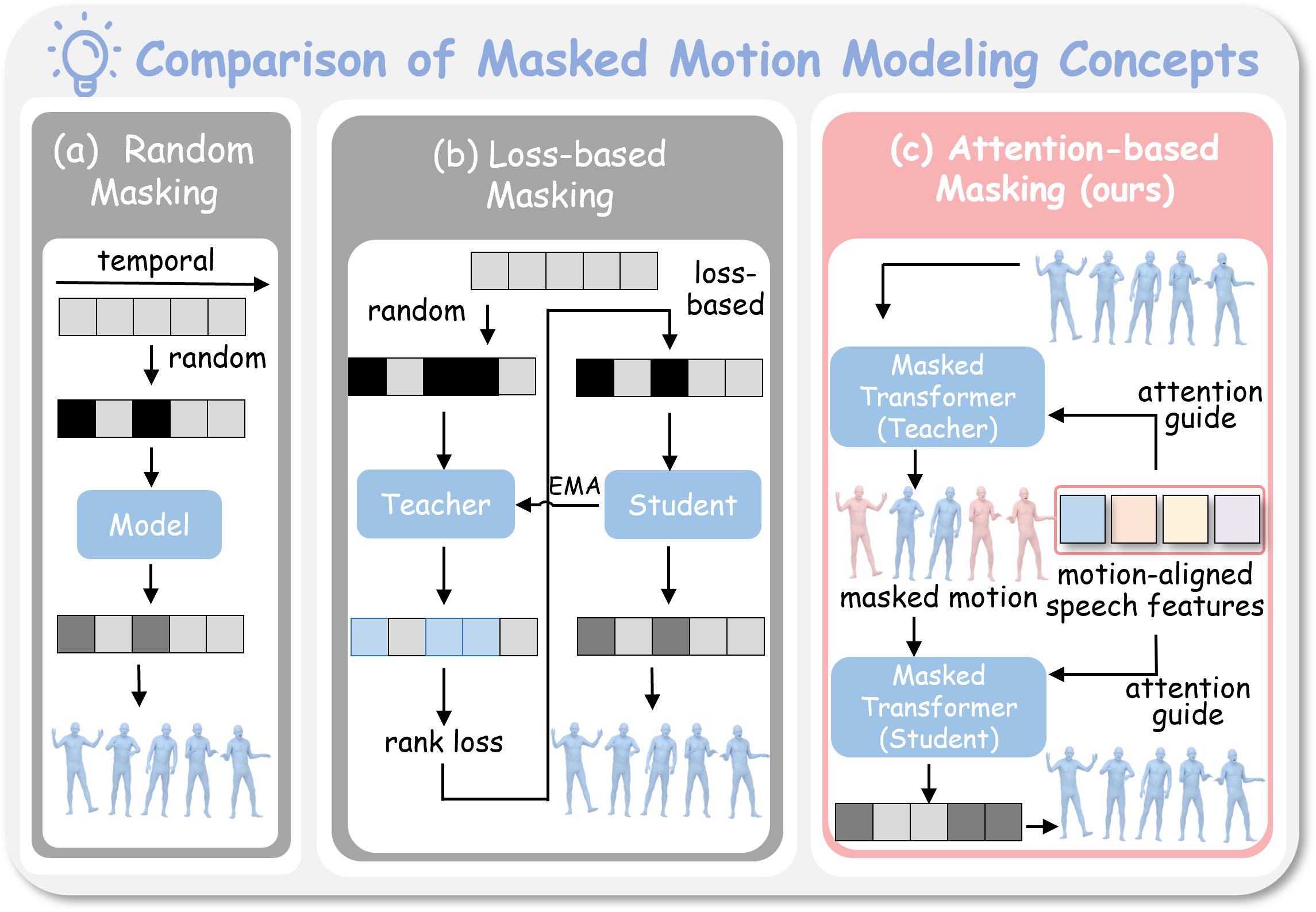
Xiangyue Zhang, Jianfang Li, Jiaxu Zhang, Jianqiang Ren, Liefeng Bo, Zhigang Tu*.
EchoMask: Speech-Queried Attention-based Mask Modeling for Holistic Co-Speech Motion Generation.
ACM MM, 2025.
(通讯作者, CCF-A类会议,多媒体领域顶会)
PDF
Zhigang Tu, Zhengbo Zhang, Jia Gong, Junsong Yuan, Bo Du.
Informative Sample Selection Model for Skeleton-based Action Recognition with Limited Training Samples.
IEEE Transactions on Image Processing , 2025.
(第一作者, IF=13.7, CCF A类期刊/中科院1区Top)
PDF
Zhigang Tu, Zhengbo Zhang*, Zitao Gao, Chunluan Zhou, Junsong Yuan, Bo Du.
FADE: A Dataset for Detecting Falling Objects around Buildings in Video.
IEEE Transactions on Information Forensics and Security (TIFS) , 2025.
(第一作者, 信息安全顶刊, IF=8.0, CCF A类期刊/中科院1区Top)
PDF
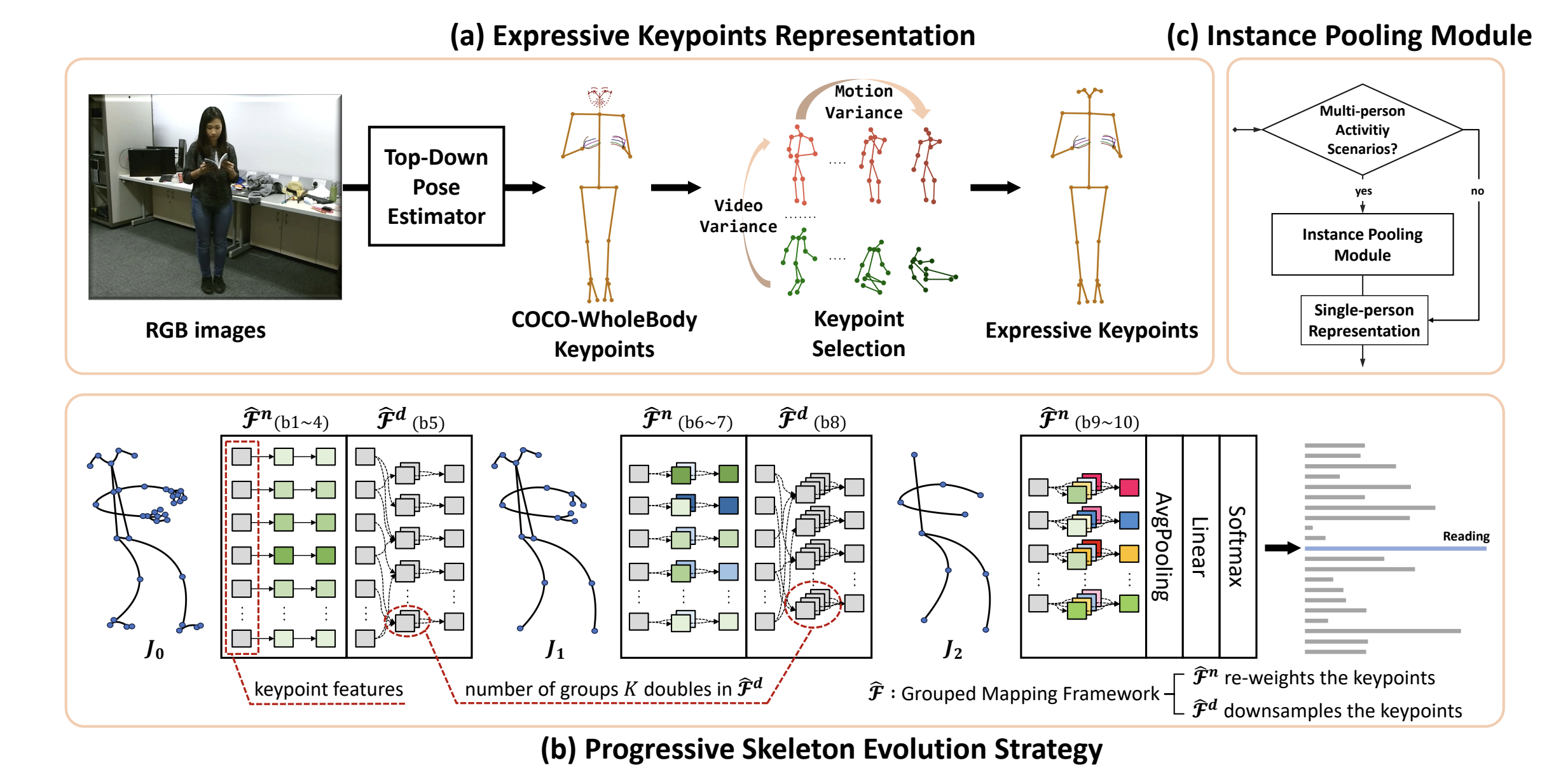
Yijie Yang, Jinlu Zhang, Jiaxu Zhang, Bo Du, Zhigang Tu*.
Expressive Keypoints for Skeleton-based Action Recognition via Progressive Skeleton Evolution.
IEEE Transactions on Image Processing , 2025.
(通讯作者, IF=13.7, CCF A类期刊/中科院1区Top)
PDF
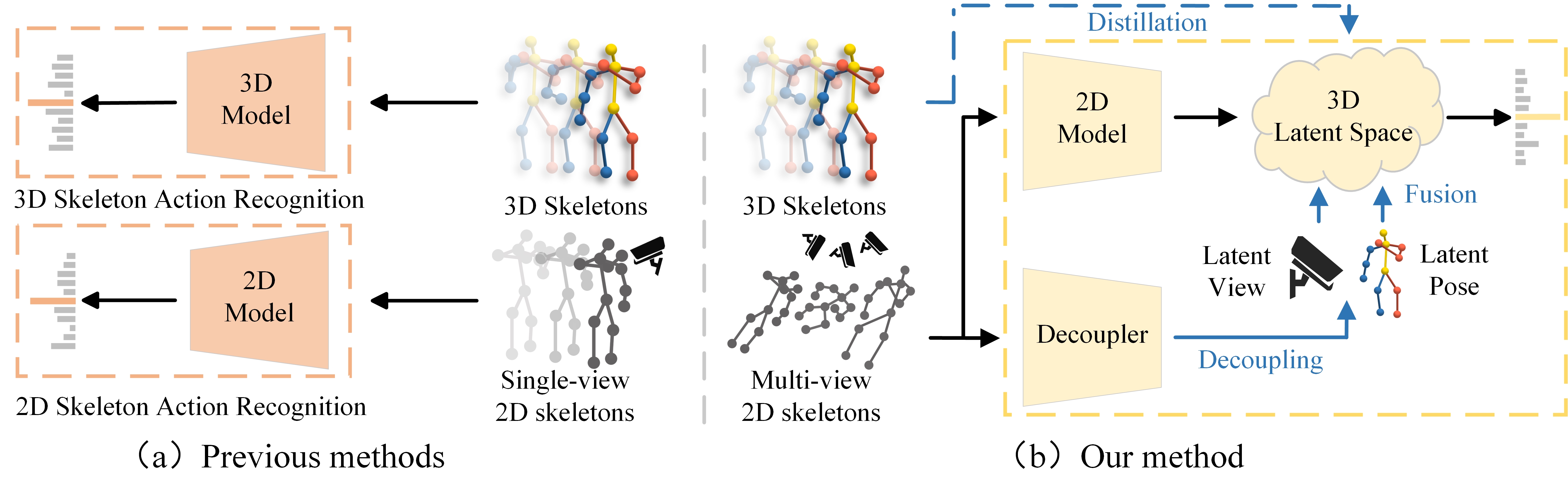
Xiangyue Zhang, Yifan Jia, Jiaxu Zhang, Yijie Yang, Zhigang Tu*.
Robust 2D Skeleton Action Recognition via Decoupling and Distilling 3D Latent Features.
IEEE Transactions on Circuits and Systems for Video Technology, 2025.
(通讯作者, IF=11.1, 中科院1区top)
PDF
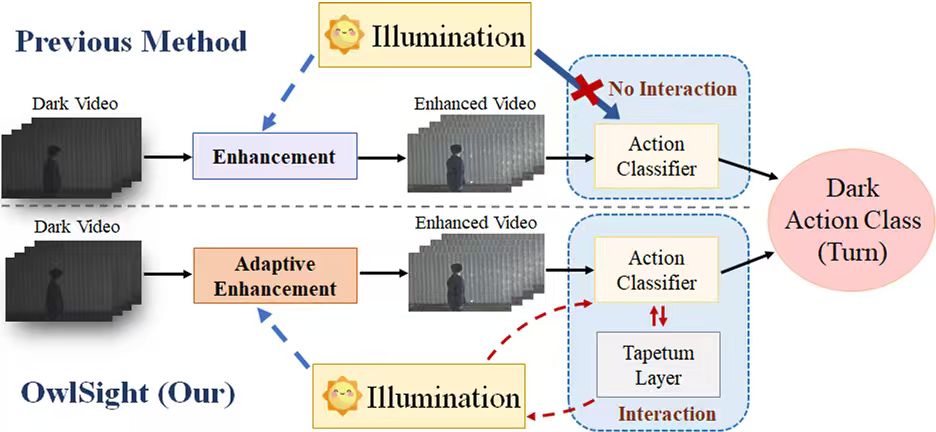
Shihao Cheng, Jinlu Zhang, Yue Liu, Aoran Xiao, Zhigang Tu*.
OwlSight: A Robust Illumination Adaptation Framework for Dark Video Human Action Recognition.
IEEE Transactions on Circuits and Systems for Video Technology, 2025.
(通讯作者, IF=11.1, 中科院1区top)
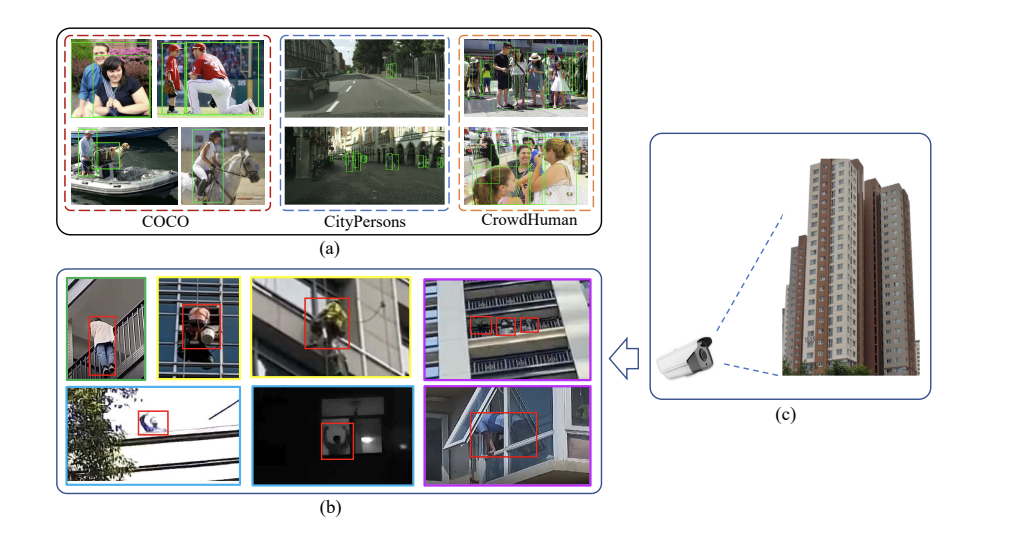
Zitao Gao, Bing Qu, Chunluan Zhou, Junsong Yuan, Zhigang Tu*.
EBPersons: A Dataset for Person Detection at the Edges of Buildings.
IEEE Transactions on Multimedia , 2025.
(通信作者,IF=9.9, 中科院1区Top)
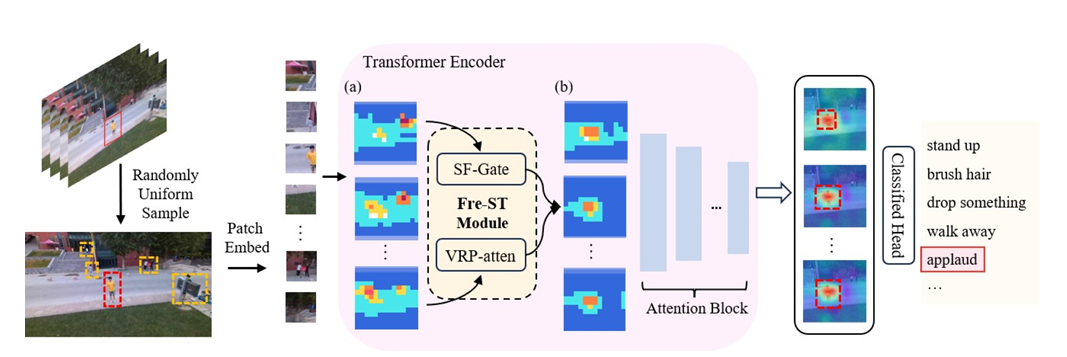
Tianqi Xiang, Xinghui Xia, Junsong Yuan, Zhigang Tu*.
Fre-STformer: A Frequency-based Spatio-Temporal Transformer for UAV Human Action Recognition.
IEEE Transactions on Multimedia , 2025.
(通信作者,IF=9.9, 中科院1区Top)
2024
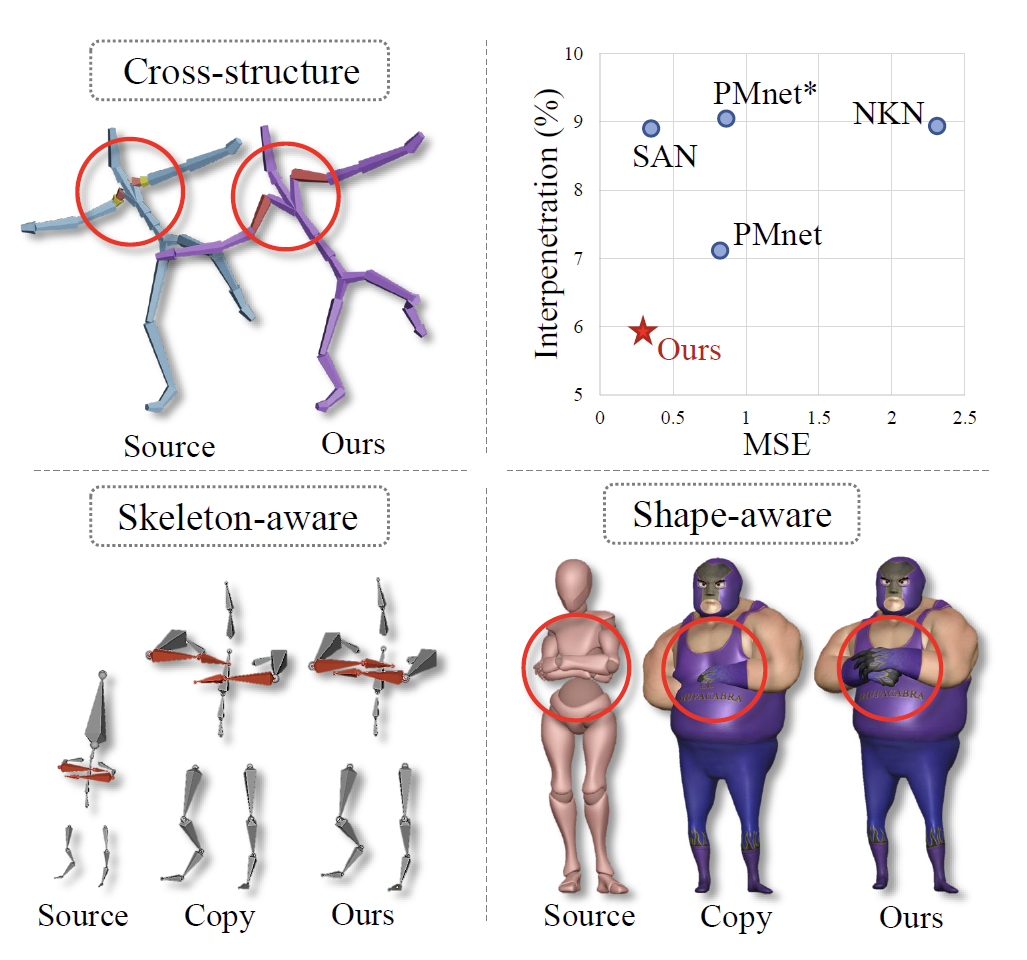
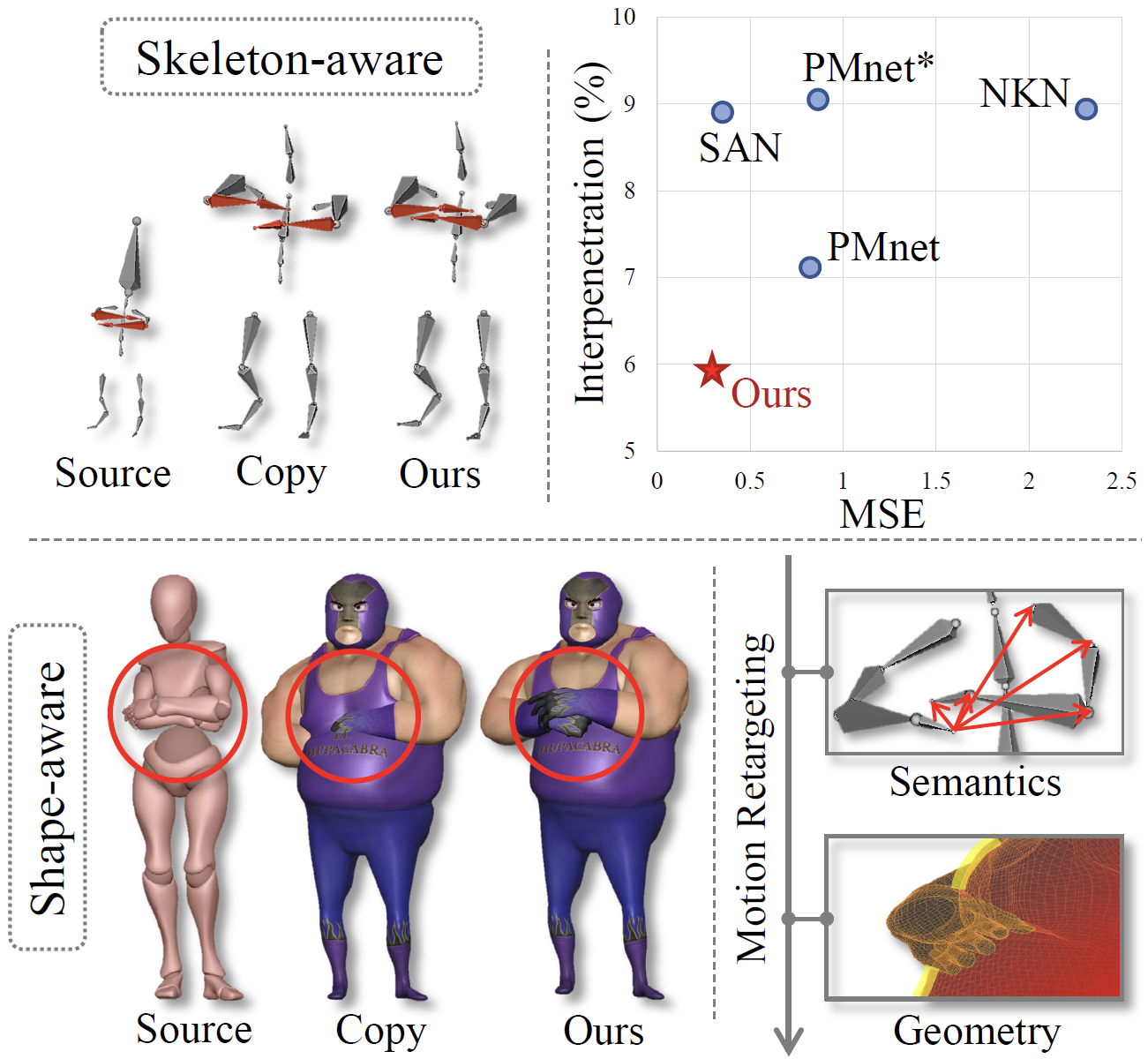
Jiaxu Zhang, Zhigang Tu*, Junwu Weng, Junsong Yuan, Bo Du.
A Modular Neural Motion Retargeting System Decoupling Skeleton and Shape Perception.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2024. (通讯作者, IF=24.314, CCF A类期刊/中科院1区Top)
PDF
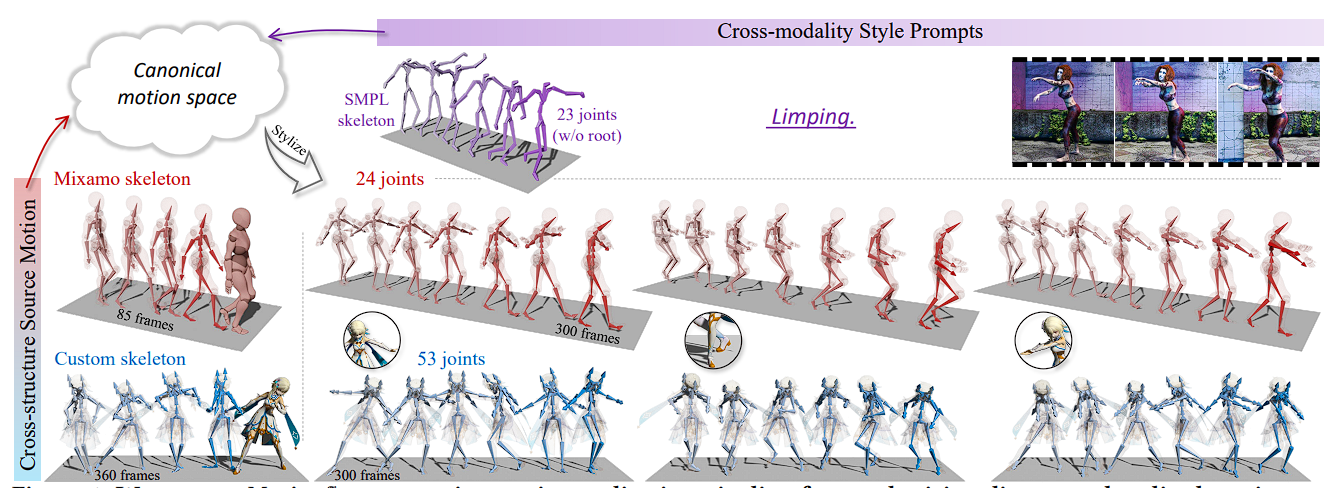
Jiaxu Zhang, Xin Chen, Gang Yu, Zhigang Tu*.
Generative Motion Stylization of Cross-structure Characters within Canonical Motion Space.
ACM Multimedia , 2024.
(通讯作者, CCF-A类会议,多媒体领域顶会)
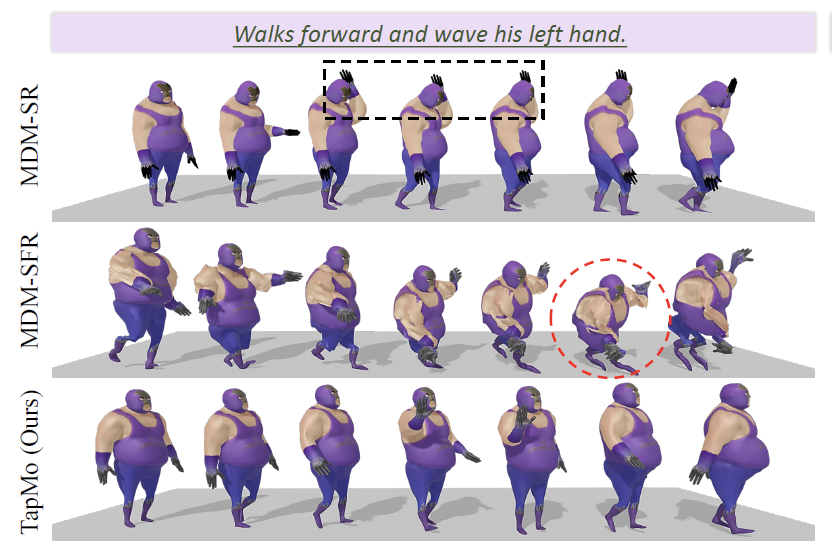
Jiaxu Zhang#, Shaoli Huang#, Zhigang Tu*, et.al.
TapMo: Shape-aware Motion Generation of Skeleton-free Characters.
ICLR, 2024. (通讯作者, 机器学习排名第一顶会)
PDF
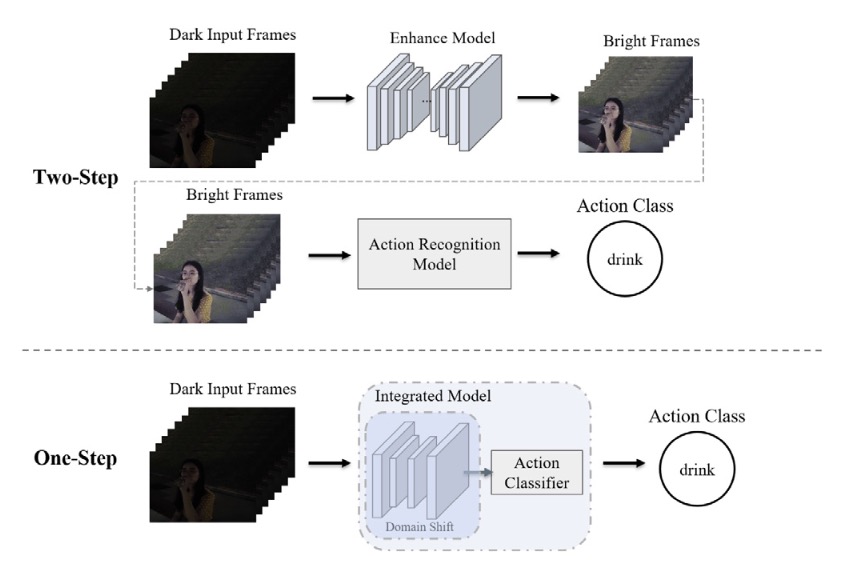
Yuwei Yin, Miao Liu, Renjie Yang, Yuanzhong Liu, Zhigang Tu*.
Dark-DSAR: Lightweight one-step pipeline for action recognition in dark videos.
Neural Networks, 2024. (通讯作者, IF=6.0, 中科院1区)
PDF
2023
Zhigang Tu, Zhisheng Huang, Yujin Chen, Di Kang, Linchao Bao, Bisheng Yang, Junsong Yuan.
Consistent 3D Hand Reconstruction in Video via Self-Supervised Learning.
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 45(8): 9469-9485, 2023. (第一作者, IF=24.314, CCF A类期刊/中科院1区Top)
PDF
Zhigang Tu, Yuanzhong Liu, Yan Zhang, Qizi Mu, Junsong Yuan.
DTCM: Joint Optimization of Dark Enhancement and Action Recognition in Videos.
IEEE Transactions on Image Processing (TIP), 2023.
(第一作者, IF=11.041,CCF A类期刊/中科院1区Top).
PDF
Songlian Li, Min Hu, Xiongwu Xiao, Zhigang Tu*.
Patch Similarity Self-Knowledge Distillation for Cross-view Geo-localization.
IEEE Transactions on Circuits and Systems for Video Technology, 2023. (通讯作者, IF=8.4, 中科院1区)
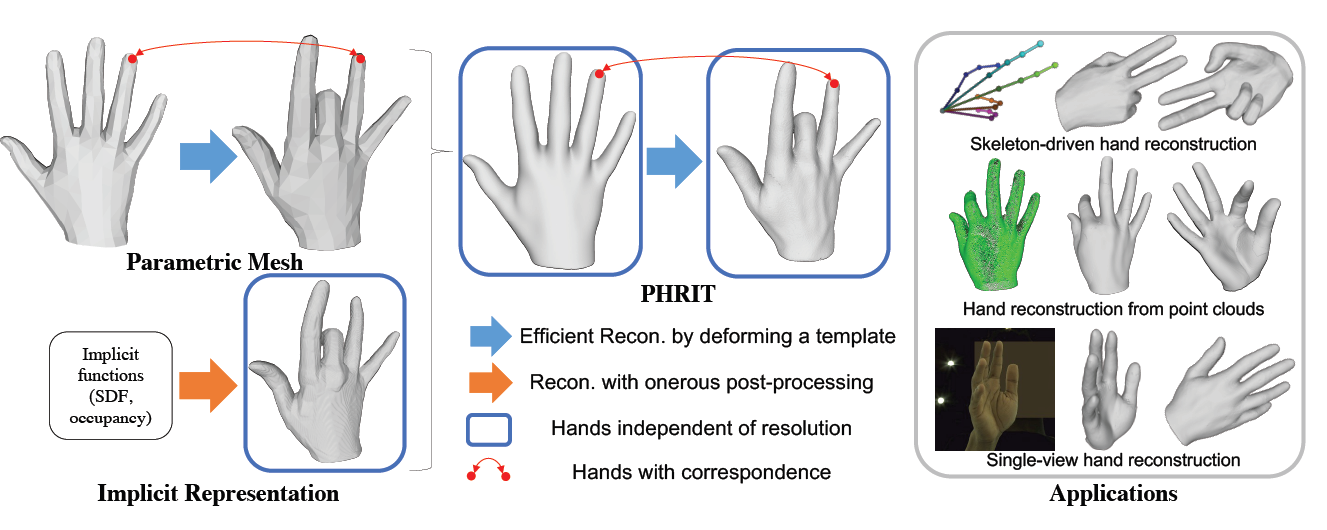
Zhisheng Huang, Yujin Chen, Di Kang, Jinlu Zhang, Zhigang Tu*.
PHRIT: Parametric Hand Representation with Implicit Template.
ICCV, 2023.
(通讯作者, CCF-A类会议,人工智能&计算机视觉三大顶会之一)
Jiaxu Zhang, Junwu Weng, Di Kang, Fang Zhao, Shaoli Huang, Xuefei Zhe, Linchao Bao, Ying Shan, Jue Wang and Zhigang Tu*.
Skinned Motion Retargeting with Residual Perception of Motion Semantics & Geometry.
CVPR, 2023. (通讯作者, CCF-A类会议,人工智能&计算机视觉三大顶会之一)
2022
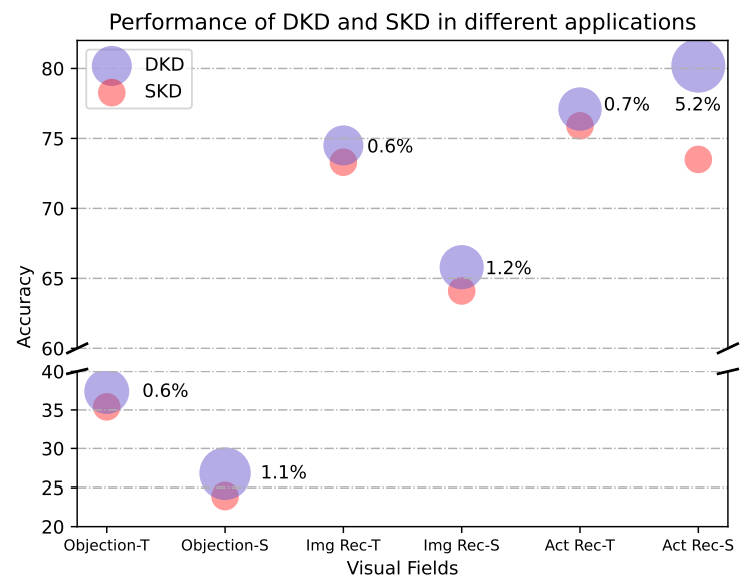
Zhigang Tu, Xiangjian Liu, and Xuan Xiao.
A General Dynamic Knowledge Distillation Method for Visual Analytics.
IEEE Transactions on Image Processing (TIP), 2022.
(第一作者, IF=11.041,CCF A类期刊/中科院1区Top).
PDF
Yuanzhong Liu, Junsong Yuan, and Zhigang Tu*.
Motion-driven Visual Tempo Learning for Video-based Action Recognition.
IEEE Transactions on Image Processing (TIP), 2022.
(通讯作者, IF=11.041,CCF A类期刊/中科院1区Top)
PDF
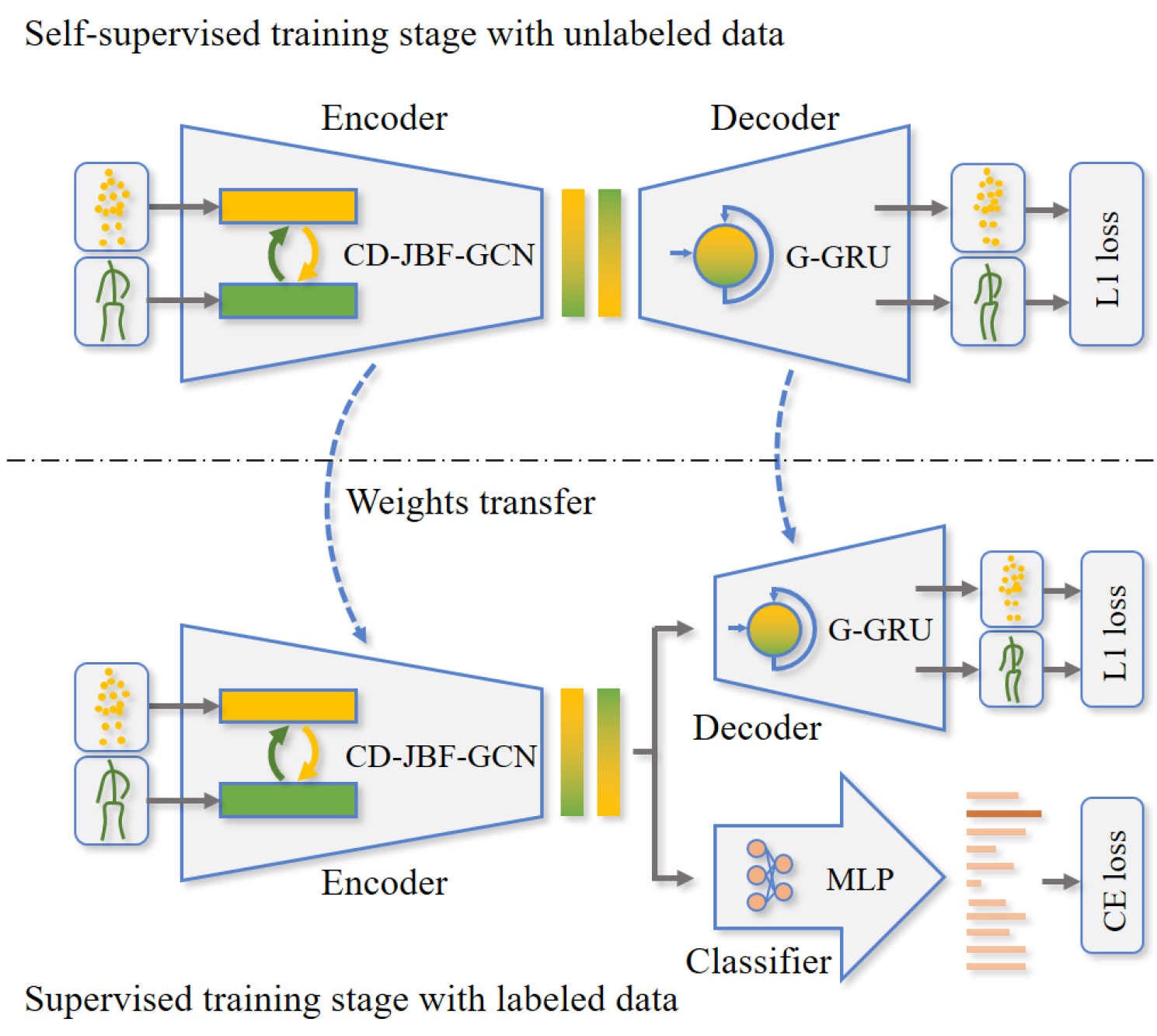
Zhigang Tu, Jiaxu Zhang*, Hongyan Li, Yujin Chen, and Junsong Yuan.
Joint-bone Fusion Graph Convolutional Network for Semi-supervised Skeleton Action Recognition.
IEEE Transactions on Multimedia (TMM), 2022. (第一作者, IF=8.182,中科院1区Top)
Jiaxu Zhang, Yifan Jia, Wei Xie, Zhigang Tu*.
Zoom Transformer for Skeleton-based Group Activity Recognition.
IEEE Transactions on Circuits and Systems for Video Technology, 2022.
(通讯作者, IF=5.859,中科院1区).
PDF
Jinlu Zhang, Zhigang Tu*, Jianyu Yang, Yujin Chen, and Junsong Yuan.
MixSTE: Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video.
CVPR, 2022. (通讯作者, CCF A类会议, CV&AI三大顶会之一)
PDFCodeVideoSlide
Jinlu Zhang, Yujin Chen and Zhigang Tu*.
Uncertainty-Aware 3D Human Pose Estimation from Monocular Video.
ACM Multimedia, 2022.
(通讯作者, CCF A类会议,多媒体领域顶会)
Zhengbo Zhang, Chunlan Zhou, Zhigang Tu*.
Distilling Inter-Class Distance for Semantic Segmentation.
IJCAI, 2022. (通讯作者, CCF A类会议,Oral)
PDF
Zhigang Tu, Hongyan Li, Wei Xie, Yuanzhong Liu, Shifu Zhang, Baoxin Li, and Junsong Yuan.
Optical Flow for Video Super-Resolution: A Survey. Artificial Intelligence Review (AIR), 2022.
(第一作者, IF=13.9, 中科院1区Top)
Songlian Li, Zhigang Tu*, Yujin Chen, Tan Yu.
Multi-scale attention encoder for street-to-aerial image geo-localization.
CAAI Transactions on Intelligence Technology, pp.1-11, 2022.
(通讯作者, IF=7.985, 中国人工智能学会会刊)
PDF
2021
Yunpeng Chang, Zhigang Tu*, Bin Luo, and Junsong Yuan.
Video Anomaly Detection with Spatio-Temporal Dissociation.
Pattern Recognition(PR) , vol.122, pp.108213:1-12, Feb. 2022.
(通讯作者,IF=8.518,中科院1区Top)
PDF
Yujin Chen, Zhigang Tu*, Di Kang, Linchao Bao, Ying Zhang, Xuefei Zhe, Ruizhi Chen, Junsong Yuan.
Model-based 3D Hand Reconstruction via Self-Supervised Learning. CVPR, pp.10451-10460, 2021.
(通讯作者, CCF A类会议, CV&AI三大顶会之一).
PDF
Yujin Chen, Zhigang Tu#, Di Kang, Ruizhi Chen, Linchao Bao*, Zhengyou Zhang, and Junsong Yuan.
Joint Hand-object 3D Reconstruction from a Single Image with Cross-branch Feature Fusion.
IEEE Transactions on Image Processing(TIP), vol.30, pp.4008-4021, 2021.
(共同第一作者, IF=11.041, CCF A类期刊,中科院1区Top).
PDF
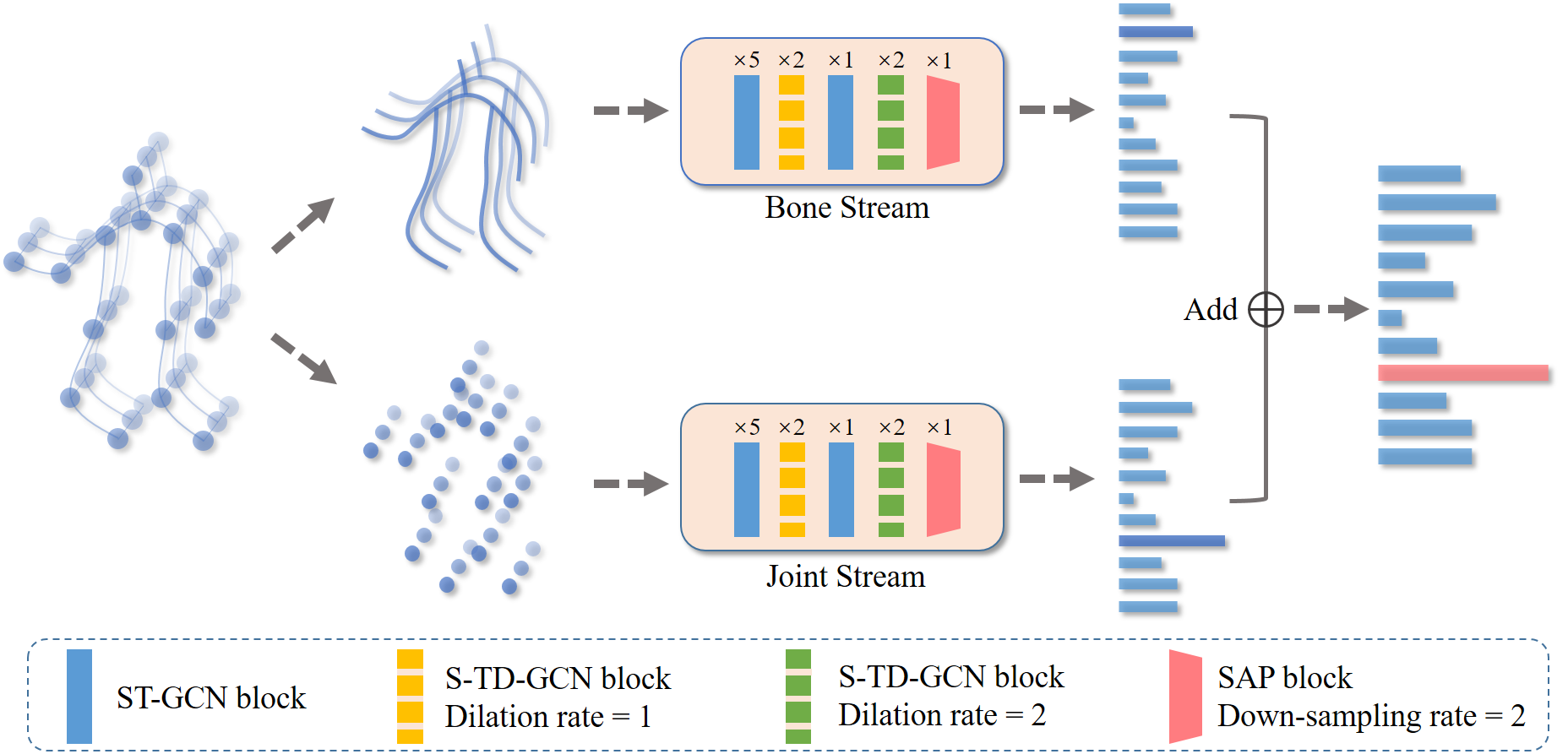
Jiaxu Zhang, Gaoxiang Ye, Zhigang Tu*, Yongtao Qin, Qianqing Qin, Jinlu Zhang, and Jun Liu.
A Spatial Attentive and Temporal Dilated (SATD) GCN for Skeleton-Based Action Recognition.
CAAI Transactions on Intelligence Technology, Sep. 2021.(通讯作者, IF=7.985, 中国人工智能学会会刊)
PDF
2020
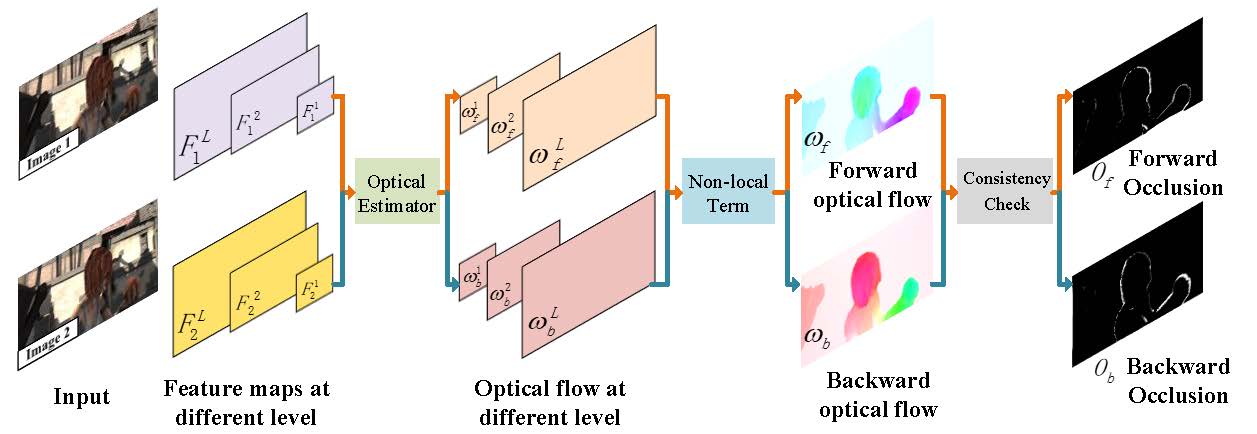
Long Tian, Zhigang Tu*, Dejun Zhang, Jun Liu, Baoxin Li, and Junsong Yuan.
Unsupervised Learning of Optical Flow With CNN-based Non-Local Filtering.
IEEE Transactions on Image Processing (TIP), vol.29, pp.8429-8442. 2020. (通讯作者, IF=11.041, CCF A类期刊, 中科院1区Top).
PDF
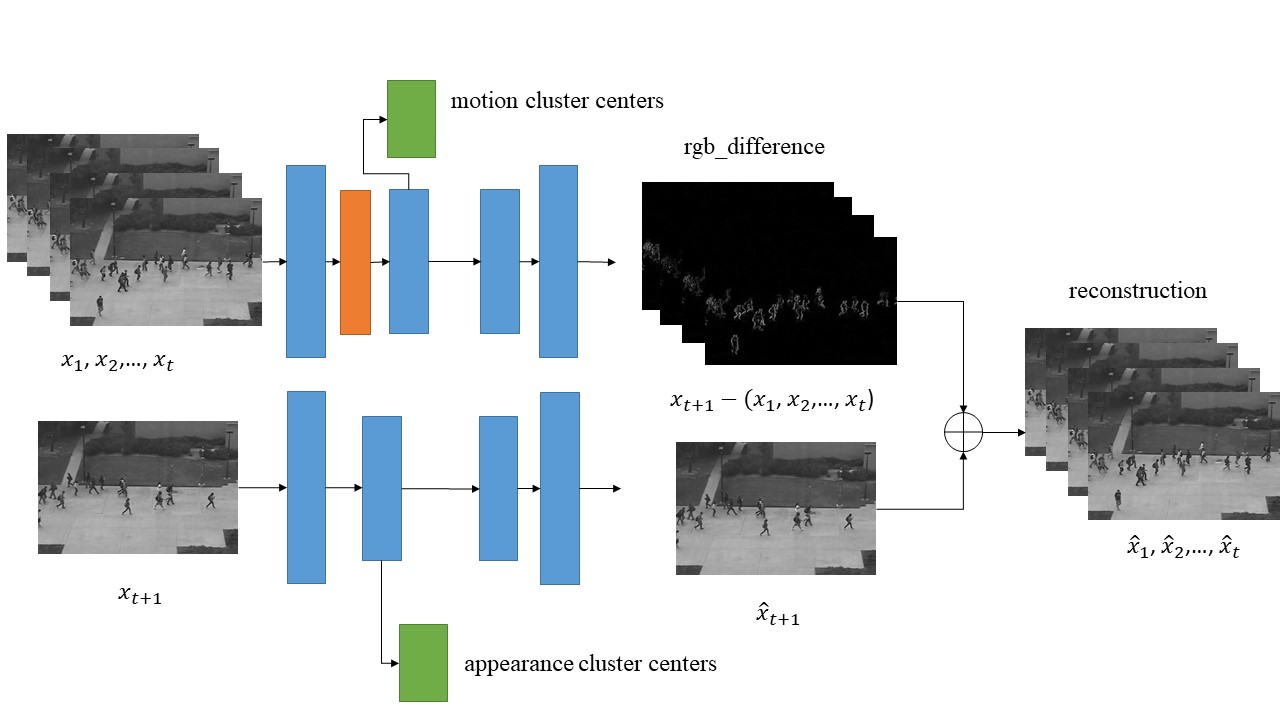
Yunpeng Chang, Zhigang Tu*, Wei xie, Junsong Yuan. Clustering-driven Deep Autoencoder for Video Anomaly Detection.
ECCV 2020 (通讯作者, CCF B类会议, CV&AI三大顶会之一).
PDF
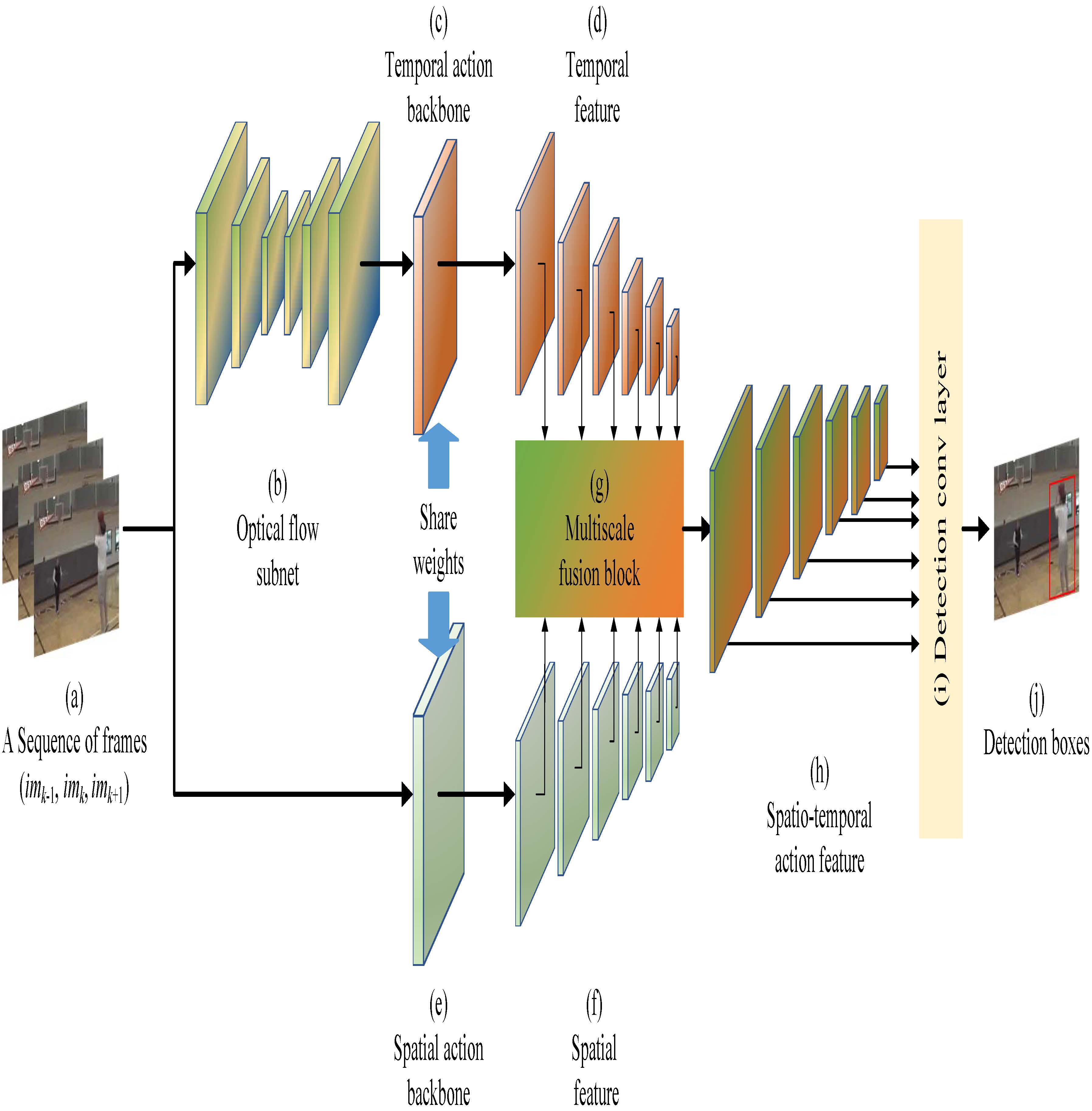
Dejun Zhang*, Linchao He, Zhigang Tu*, Shifu Zhang, Fei Han, and Boxiong Yang.
Learning Motion Representation for Real-Time Spatio-Temporal Action Localization.
Pattern Recognition, vol.103, pp.107312:1–10, 2020 (通讯作者, IF=8.518 中科院1区Top).
PDF
Yujin Chen, Zhigang Tu*, Liuhao Ge, Dejun Zhang, Ruizhi Chen, and Junsong Yuan.
SO-HandNet: Self-Organizing Network for 3D Hand Pose Estimation with Semi-supervised Learning. ICCV, 2019
(通讯作者, CCF A类会议, CV&AI三大顶会之一).
PDFCodeProjectSlide
Zhigang Tu, Hongyan Li*, Dejun Zhang, Justin Dauwels, Baoxin Li, and Junsong Yuan. Action-Stage Emphasized Spatio-Temporal VLAD for Video Action Recognition. IEEE Transactions on Image Processing (TIP), 28(6): 2799–2812, 2019. (IF=11.041, CCF A类期刊, 中科院1区TOP).PDF
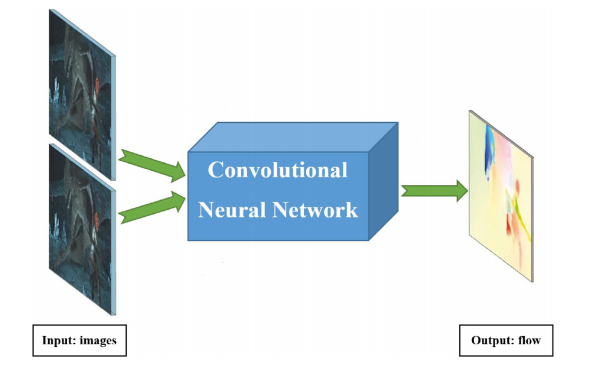
Zhigang Tu*, Wei Xie*, Dejun Zhang, Ronald Poppe, Remco C. Veltkamp, Baoxin Li, and Junsong Yuan. A survey of variational and CNN-based optical flow techniques. Signal Processing: Image Communication, vol.72, pp.9–24, March 2019. (综述,热点论文,IF=3.256).PDF
Zhigang Tu*, Wei Xie, Justin Dauwels, Baoxin Li, and Junsong Yuan.
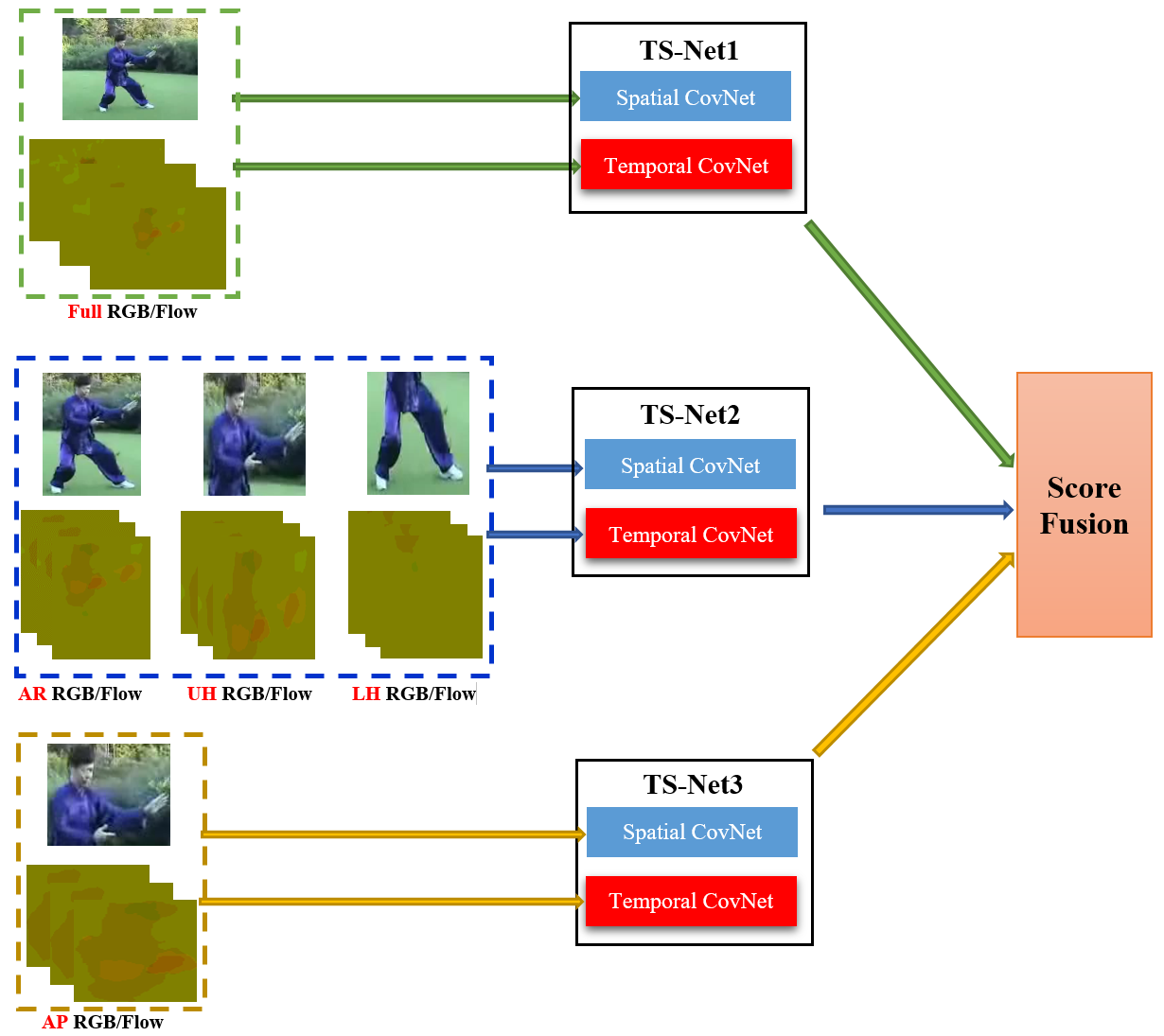
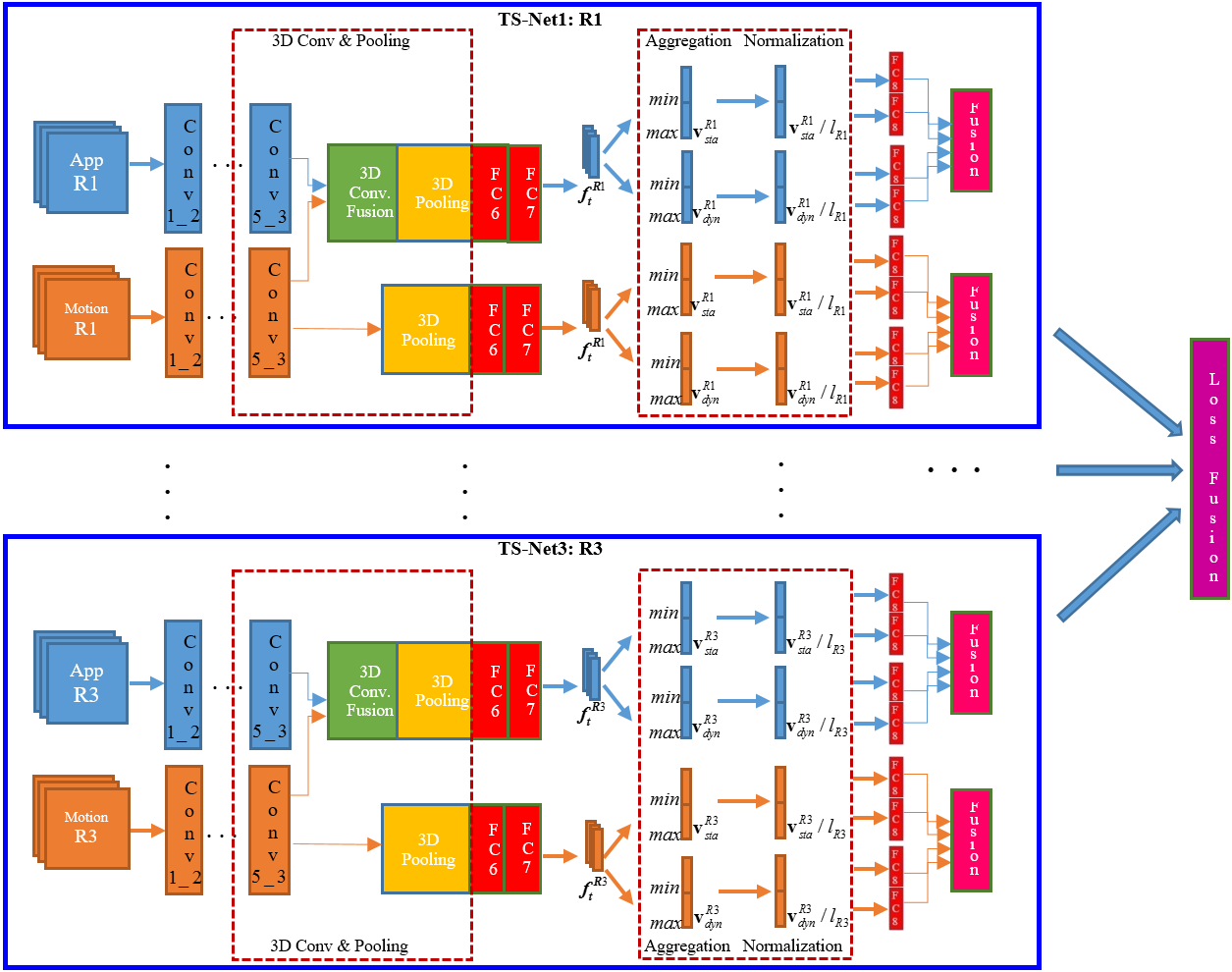
Semantic Cues Enhanced Multi-modality Multi-Stream CNN for Action Recognition.
IEEE Transactions on Circuits and Systems for Video Technology (T-CSVT), 29(5): 1423–1437,
2019. (IF=5.859,中科院2区)PDF
Zhigang Tu, Wei Xie, Qianqing Qin, Remco C. Veltkamp, Baoxin Li, and Junsong Yuan. Multi-Stream CNN: Learning Representations Based on Human-Related Regions for Action Recognition. Pattern Recognition(PR), vol.79, pp.32–43, 2018. (IF=8.518,中科院1区TOP).
PDF
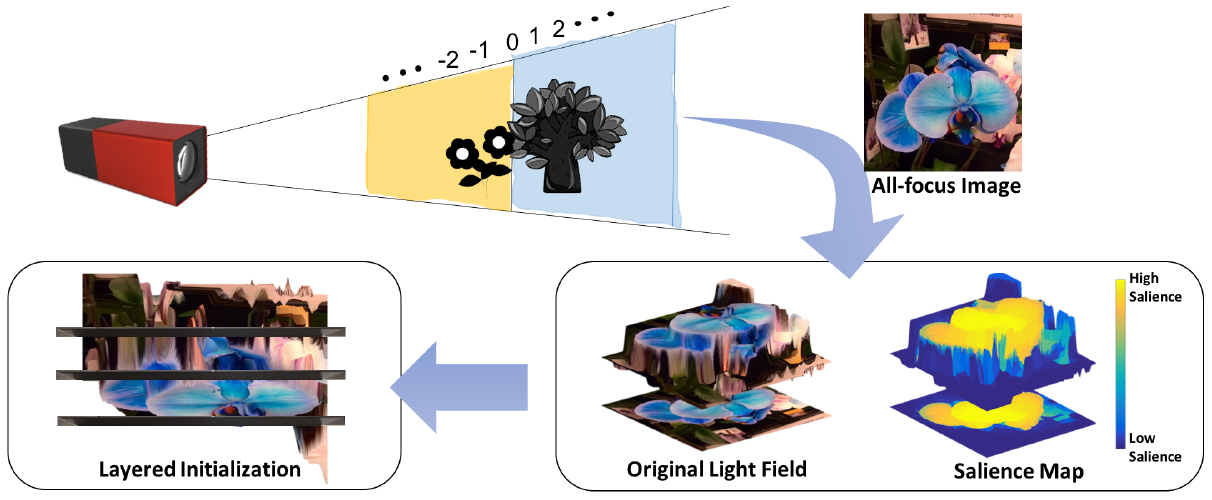
Shizheng Wang, Wenjuan Liao, Zhigang Tu, Yuanjin Zheng, and Junsong Yuan. Salience Guided Depth Calibration for Perceptually Optimized Compressive Light Field 3D Display. In Proc. Comput. Vis. Pattern Recogn. (CVPR), 2018. (CCF A类会议).
PDF
Zhigang Tu, Zuwei Guo, Wei Xie, Mengjia Yan, Remco. C. Veltkamp, Baoxin Li, and Junsong Yuan. Fusing disparate object signatures for salient object detection in video. Pattern Recognition(PR), vol.72, pp.285–299, 2017.(IF=8.518,中科院1区TOP)
PDF
Zhigang Tu, Wei Xie, C. Gemeren, and Remco C. Veltkamp. Variational Method for Joint Optical Flow Estimation and Edge-aware Image Restoration. Pattern Recognition(PR), vol.65, pp.11–25, 2017.(IF=8.518,中科院1区TOP)
PDF
Zhigang Tu, Ronald Poppe, and Remco C. Veltkamp. Weighted Local Intensity Fusion Method for Variational Optical Flow Estimation. Pattern Recognition(PR), vol.50, pp.223–232, 2016.(IF=8.518,中科院1区TOP)
PDF
Zhigang Tu, Nico. Aa, C. Gemeren, and Remco C. Veltkamp. A combined post-filtering method to improve accuracy of variational optical flow estimation. Pattern Recognition(PR), vol.47, no.5, pp.1926–1940, 2014. (IF=8.518,中科院1区TOP)
PDF
Zhigang Tu, Ronald Poppe, and Remco C. Veltkamp. Adaptive Guided Image Filter for Warping in Variational Optical Flow. Signal Processing, vol.127, pp.253–265, 2016.(IF=4.662,中科院2区)
PDF
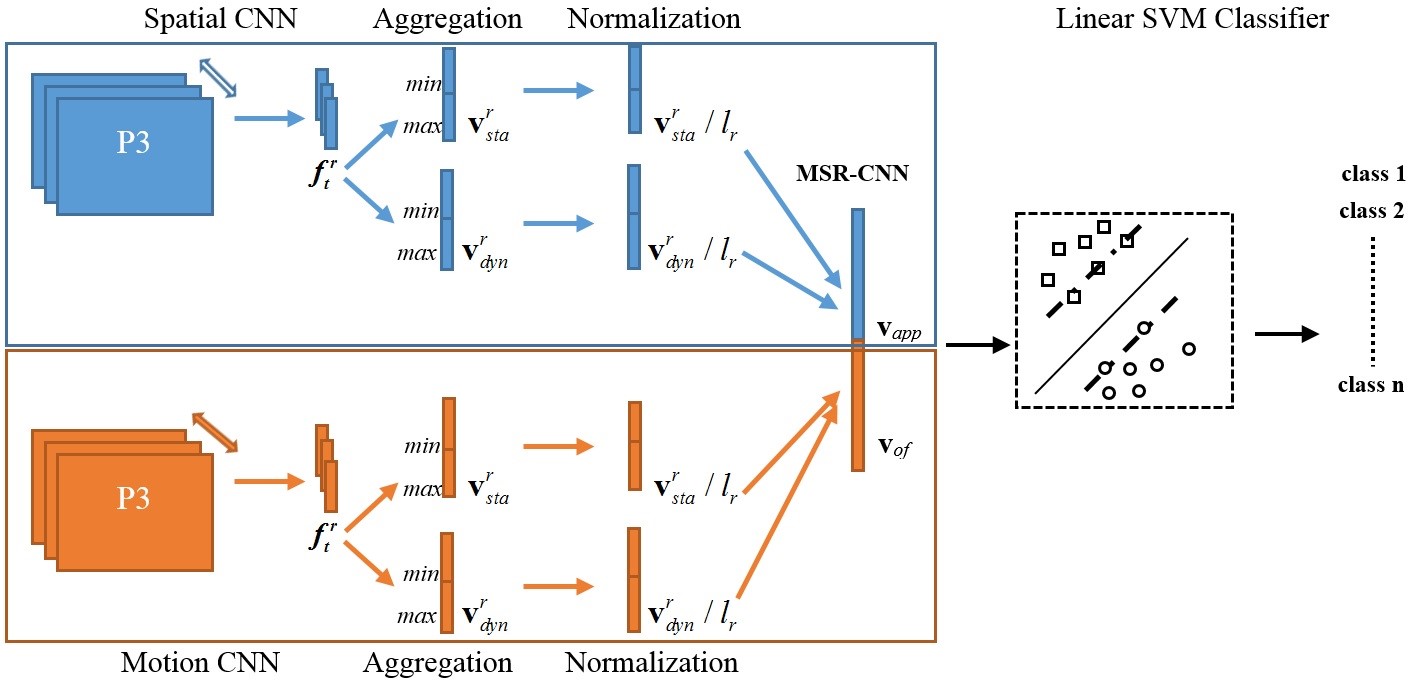
Zhigang Tu, Yikang Li, Jun Cao, and Baoxin Li. MSR-CNN: Applying Motion Salient Region Based Descriptors for Action Recognition. In Proc. Int. Conf. Pattern Recogn. (ICPR), pp. 3524–3529, 2016. (CCF C类会议).).
PDF
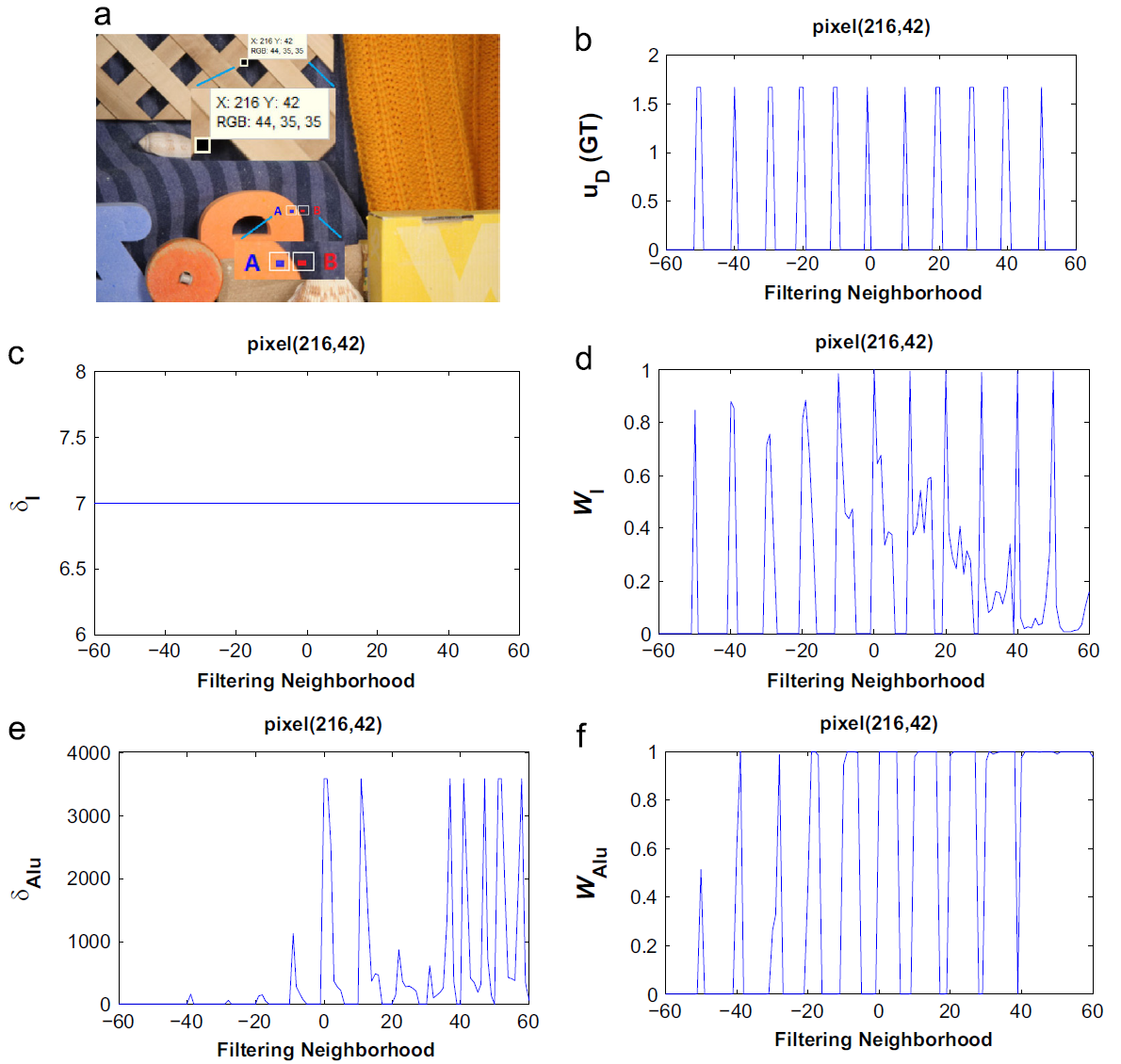
Zhigang Tu, Coert Van Gemeren, and Remco C. Veltkamp. Improved color patch similarity measure based weighted median filter. In Proc. Asian Conf. Comput. Vis. (ACCV), vol.9007, pp.413–427, 2015[C](CCF C类会议).
PDF
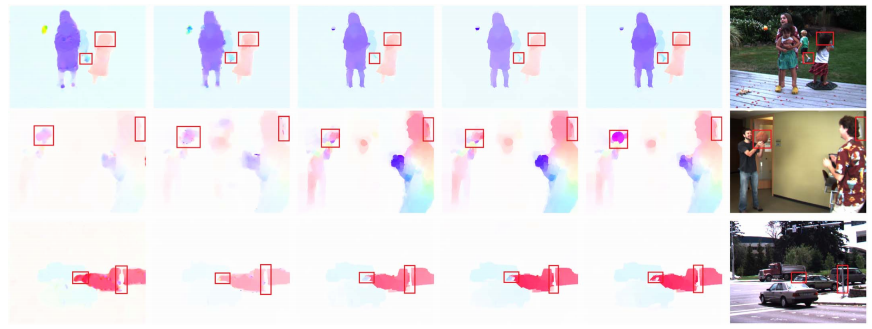
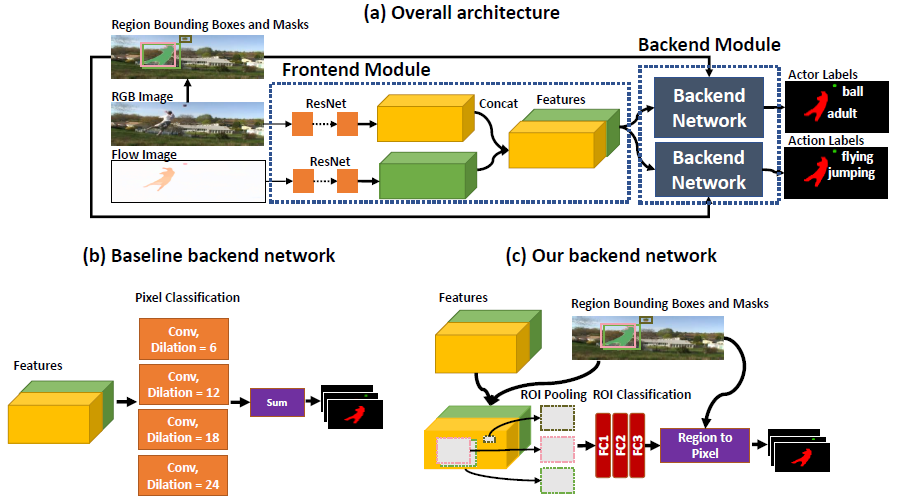
Kang Dang, Chunluan Zhou, Zhigang Tu, Justin Dauwels, and Junsong Yuan. Actor-Action Semantic Segmentation with Region Masks. In Proc. The British Machine Vis. Conf. (BMVC), 2018.(CCF C类会议).
PDF